我的作品 Python 爬虫微框架 web-craft
happytaoer(Tao)
·
2025年10月20日
·
133 次阅读
背景
这两天构思了一个爬虫框架,对外提供 API 创建爬虫任务,然后内部的队列会进行爬虫的消费。只需要实现数据的解析接口就能快速编写爬虫。非常适合需要利用 AI 快速生成爬虫代码的团队。
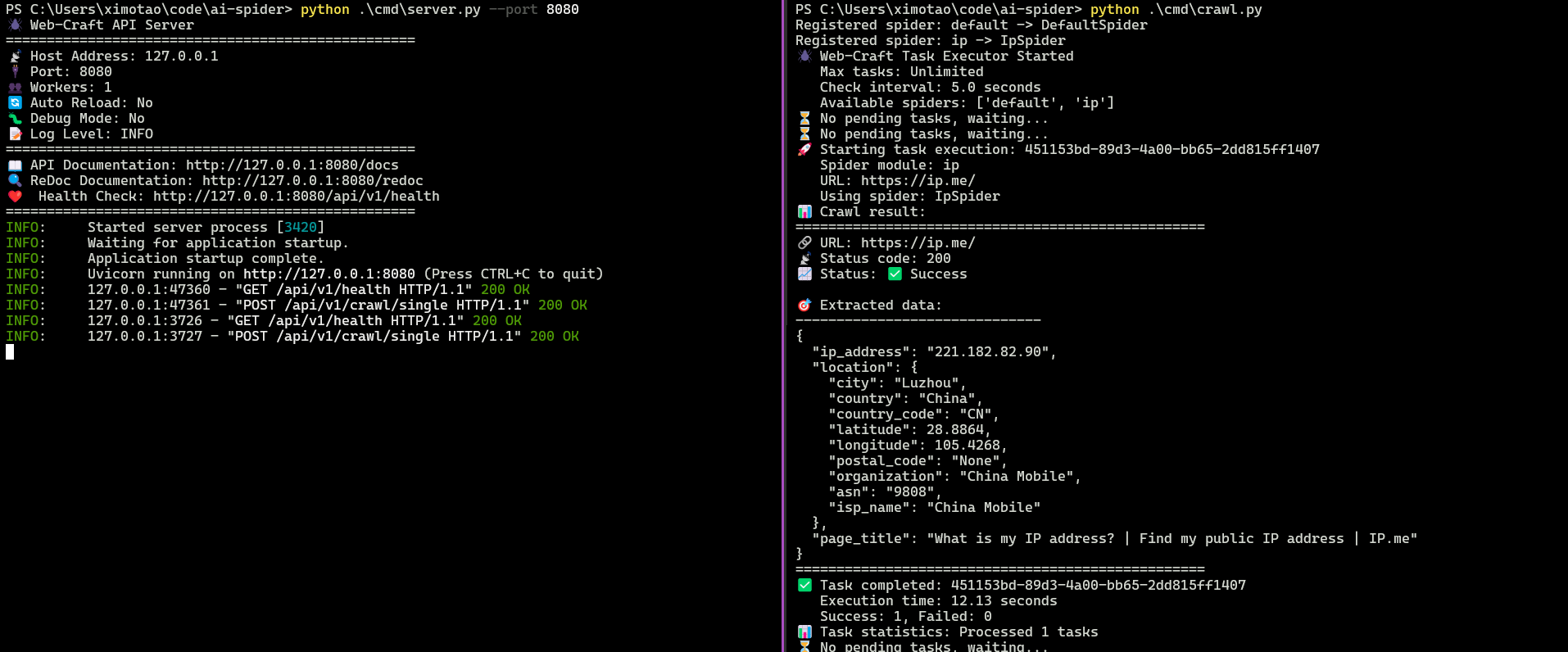
这个框架对外提供了 API 接口来创建,非常便利。目前的设计思路就是只需要实现一个 parse 接口,就行了,方便后续 AI 的介入。
后续开发计划
- 开放 AI 接口,通过 AI 自动生成爬虫代码
- 集成基于 redis 的任务队列
- 实现对外输出的接口层,例如爬虫结果转储到 mysql 等。
目前这是一个非常简单清晰的项目,希望和感兴趣的朋友共建这个项目,提升大家的技术影响力,或许对找远程工作也是有帮助的。
暂无回复。